How to use the ExperimentManager¶
It’s the element that allows you to make your experiments on Agent and Environment. You can use it to train, optimize hyperparameters, evaluate, compare, and gather statistics about your agent on a specific environment. You can find the API doc here. It’s not the only solution, but it’s the compact (and recommended) way of doing experiments with an agent.
For this example, you will use the “PPO” torch agent from “StableBaselines3” and wrap it in rlberry Agent. To do that, you need to use StableBaselinesAgent. More information here.
Create your experiment¶
from rlberry.envs import gym_make
from rlberry.agents.stable_baselines import StableBaselinesAgent
from stable_baselines3 import PPO
from rlberry.manager import ExperimentManager, evaluate_agents
env_id = "CartPole-v1" # Id of the environment
env_ctor = gym_make # constructor for the env
env_kwargs = dict(id=env_id) # give the id of the env inside the kwargs
first_experiment = ExperimentManager(
StableBaselinesAgent, # Agent Class to manage stableBaselinesAgents
(env_ctor, env_kwargs), # Environment as Tuple(constructor,kwargs)
init_kwargs=dict(algo_cls=PPO, verbose=1), # Init value for StableBaselinesAgent
fit_budget=int(100), # Budget used to call our agent "fit()"
eval_kwargs=dict(
eval_horizon=1000
), # Arguments required to call rlberry.agents.agent.Agent.eval().
n_fit=1, # Number of agent instances to fit.
agent_name="PPO_first_experiment" + env_id, # Name of the agent
seed=42,
)
first_experiment.fit()
output = evaluate_agents(
[first_experiment], n_simulations=5, plot=False
) # evaluate the experiment on 5 simulations
print(output)
[INFO] 09:18: Running ExperimentManager fit() for PPO_first_experimentCartPole-v1 with n_fit = 1 and max_workers = None.
Using cpu device
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
---------------------------------
| rollout/ | |
| ep_len_mean | 23.9 |
| ep_rew_mean | 23.9 |
| time/ | |
| fps | 2977 |
| iterations | 1 |
| time_elapsed | 0 |
| total_timesteps | 2048 |
---------------------------------
[INFO] 09:18: ... trained!
Using cpu device
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
[INFO] 09:18: Saved ExperimentManager(PPO_first_experimentCartPole-v1) using pickle.
[INFO] 09:18: The ExperimentManager was saved in : 'rlberry_data/temp/manager_data/PPO_first_experimentCartPole-v1_2024-04-12_09-18-10_3a9fa8ad/manager_obj.pickle'
[INFO] 09:18: Evaluating PPO_first_experimentCartPole-v1...
[INFO] Evaluation:Using cpu device
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
..... Evaluation finished
PPO_first_experimentCartPole-v1
0 89.0
1 64.0
2 82.0
3 121.0
4 64.0
Compare with another agent¶
Now you can compare this agent with another one. Here, we are going to compare it with the same agent, but with a bigger fit budget, and some fine tuning.
⚠ warning : add this code after the previous one. ⚠
second_experiment = ExperimentManager(
StableBaselinesAgent, # Agent Class
(env_ctor, env_kwargs), # Environment as Tuple(constructor,kwargs)
fit_budget=int(10000), # Budget used to call our agent "fit()"
init_kwargs=dict(
algo_cls=PPO, batch_size=24, n_steps=96, device="cpu"
), # Arguments for the Agent’s constructor.
eval_kwargs=dict(
eval_horizon=1000
), # Arguments required to call rlberry.agents.agent.Agent.eval().
n_fit=1, # Number of agent instances to fit.
agent_name="PPO_second_experiment"
+ env_id, # Name of our agent (for saving/printing)
seed=42,
)
second_experiment.fit()
output = evaluate_agents(
[first_experiment, second_experiment], n_simulations=5, plot=True
) # evaluate the 2 experiments on 5 simulations
print(output)
[INFO] 09:29: Running ExperimentManager fit() for PPO_second_experimentCartPole-v1 with n_fit = 1 and max_workers = None.
[INFO] 09:29: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 2688 | time/iterations = 27 | rollout/ep_rew_mean = 57.044444444444444 | rollout/ep_len_mean = 57.044444444444444 | time/fps = 888 | time/time_elapsed = 2 | time/total_timesteps = 2592 | train/learning_rate = 0.0003 | train/entropy_loss = -0.6261792600154876 | train/policy_gradient_loss = -0.001418954369607306 | train/value_loss = 87.49215440750122 | train/approx_kl = 0.0018317258218303323 | train/clip_fraction = 0.0 | train/loss = 31.3124942779541 | train/explained_variance = -0.33643925189971924 | train/n_updates = 260 | train/clip_range = 0.2 |
[INFO] 09:29: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 5568 | time/iterations = 57 | rollout/ep_rew_mean = 85.19354838709677 | rollout/ep_len_mean = 85.19354838709677 | time/fps = 916 | time/time_elapsed = 5 | time/total_timesteps = 5472 | train/learning_rate = 0.0003 | train/entropy_loss = -0.617610102891922 | train/policy_gradient_loss = 0.0007477130696315725 | train/value_loss = 66.27523021697998 | train/approx_kl = 1.8932236343971454e-05 | train/clip_fraction = 0.0 | train/loss = 21.402034759521484 | train/explained_variance = 0.46521711349487305 | train/n_updates = 560 | train/clip_range = 0.2 |
[INFO] 09:29: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 8640 | time/iterations = 89 | rollout/ep_rew_mean = 107.29113924050633 | rollout/ep_len_mean = 107.29113924050633 | time/fps = 946 | time/time_elapsed = 9 | time/total_timesteps = 8544 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5820738852024079 | train/policy_gradient_loss = -0.008271816929482156 | train/value_loss = 279.90625591278075 | train/approx_kl = 0.005026700906455517 | train/clip_fraction = 0.03750000102445483 | train/loss = 192.93894958496094 | train/explained_variance = 0.00014603137969970703 | train/n_updates = 880 | train/clip_range = 0.2 |
[INFO] 09:29: ... trained!
[INFO] 09:29: Saved ExperimentManager(PPO_second_experimentCartPole-v1) using pickle.
[INFO] 09:29: The ExperimentManager was saved in : 'rlberry_data/temp/manager_data/PPO_second_experimentCartPole-v1_2024-04-12_09-29-45_77245043/manager_obj.pickle'
[INFO] 09:29: Evaluating PPO_first_experimentCartPole-v1...
[INFO] Evaluation:..... Evaluation finished
[INFO] 09:29: Evaluating PPO_second_experimentCartPole-v1...
[INFO] Evaluation:..... Evaluation finished
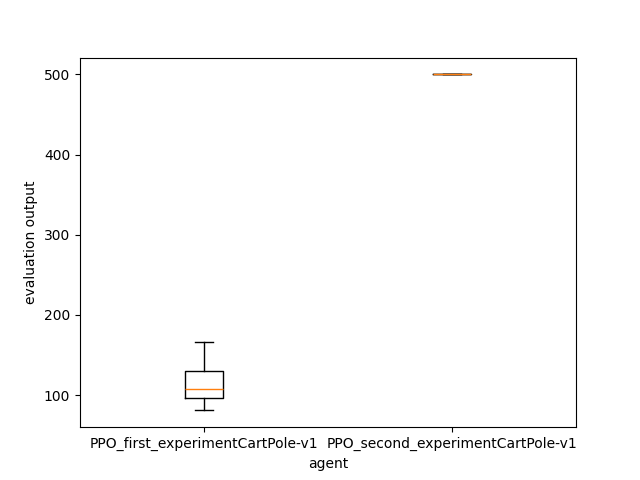
PPO_first_experimentCartPole-v1 PPO_second_experimentCartPole-v1
0 108.0 500.0
1 97.0 500.0
2 130.0 500.0
3 166.0 500.0
4 81.0 500.0
As we can see in the output or in the following image, the second agent succeed better.
Output the video¶
If you want to see the output video of the trained Agent, you need to use the RecordVideo wrapper. As ExperimentManager use tuple for env parameter, you need to give the constructor with the wrapper. To do that, you can use PipelineEnv as constructor, and add the wrapper + the env information in its kwargs.
⚠ warning : You have to do it on the ‘eval environment’, or you may have videos during the fit of your Agent. ⚠
from rlberry.envs import PipelineEnv
from gymnasium.wrappers.rendering import RecordVideo
env_id = "CartPole-v1"
env_ctor = gym_make # constructor for training env
env_kwargs = dict(id=env_id) # kwargs for training env
eval_env_ctor = PipelineEnv # constructor for eval env
eval_env_kwargs = { # kwargs for eval env (with wrapper)
"env_ctor": gym_make,
"env_kwargs": {"id": env_id, "render_mode": "rgb_array"},
"wrappers": [
(RecordVideo, {"video_folder": "./", "name_prefix": env_id})
], # list of tuple (class,kwargs)
}
third_experiment = ExperimentManager(
StableBaselinesAgent, # Agent Class
(env_ctor, env_kwargs), # Environment as Tuple(constructor,kwargs)
fit_budget=int(10000), # Budget used to call our agent "fit()"
eval_env=(eval_env_ctor, eval_env_kwargs), # Evaluation environment as tuple
init_kwargs=dict(
algo_cls=PPO, batch_size=24, n_steps=96, device="cpu"
), # settings for the Agent
eval_kwargs=dict(
eval_horizon=1000
), # Arguments required to call rlberry.agents.agent.Agent.eval().
n_fit=1, # Number of agent instances to fit.
agent_name="PPO_third_experiment" + env_id, # Name of the agent
seed=42,
)
third_experiment.fit()
output3 = evaluate_agents(
[third_experiment], n_simulations=15, plot=False
) # evaluate the experiment on 5 simulations
print(output3)
[INFO] 09:36: [PPO_third_experimentCartPole-v1[worker: 0]] | max_global_step = 1920 | time/iterations = 19 | rollout/ep_rew_mean = 44.146341463414636 | rollout/ep_len_mean = 44.146341463414636 | time/fps = 687 | time/time_elapsed = 2 | time/total_timesteps = 1824 | train/learning_rate = 0.0003 | train/entropy_loss = -0.612512381374836 | train/policy_gradient_loss = -0.004653797230503187 | train/value_loss = 75.76153821945191 | train/approx_kl = 0.008641918189823627 | train/clip_fraction = 0.03333333339542151 | train/loss = 35.162071228027344 | train/explained_variance = 0.3032127618789673 | train/n_updates = 180 | train/clip_range = 0.2 |
[INFO] 09:36: [PPO_third_experimentCartPole-v1[worker: 0]] | max_global_step = 4704 | time/iterations = 48 | rollout/ep_rew_mean = 79.20689655172414 | rollout/ep_len_mean = 79.20689655172414 | time/fps = 804 | time/time_elapsed = 5 | time/total_timesteps = 4608 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5940127298235893 | train/policy_gradient_loss = -0.016441003710982238 | train/value_loss = 154.39369611740113 | train/approx_kl = 0.010226544924080372 | train/clip_fraction = 0.07500000102445484 | train/loss = 48.81913375854492 | train/explained_variance = 0.005669653415679932 | train/n_updates = 470 | train/clip_range = 0.2 |
[INFO] 09:36: [PPO_third_experimentCartPole-v1[worker: 0]] | max_global_step = 7392 | time/iterations = 76 | rollout/ep_rew_mean = 96.08108108108108 | rollout/ep_len_mean = 96.08108108108108 | time/fps = 826 | time/time_elapsed = 8 | time/total_timesteps = 7296 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5620817124843598 | train/policy_gradient_loss = -0.0007149307257350301 | train/value_loss = 89.1684087753296 | train/approx_kl = 0.00030671278364025056 | train/clip_fraction = 0.0 | train/loss = 26.46017837524414 | train/explained_variance = 0.4496734142303467 | train/n_updates = 750 | train/clip_range = 0.2 |
[INFO] 09:36: [PPO_third_experimentCartPole-v1[worker: 0]] | max_global_step = 9984 | time/iterations = 103 | rollout/ep_rew_mean = 113.64285714285714 | rollout/ep_len_mean = 113.64285714285714 | time/fps = 832 | time/time_elapsed = 11 | time/total_timesteps = 9888 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5782853797078132 | train/policy_gradient_loss = -0.012480927801546693 | train/value_loss = 27.679842436313628 | train/approx_kl = 0.013762158341705799 | train/clip_fraction = 0.04479166660457849 | train/loss = 3.8429009914398193 | train/explained_variance = -0.32027459144592285 | train/n_updates = 1020 | train/clip_range = 0.2 |
[INFO] 09:36: ... trained!
[INFO] 09:36: The ExperimentManager was saved in : 'rlberry_data/temp/manager_data/PPO_third_experimentCartPole-v1_2024-04-12_09-36-09_da4411b3/manager_obj.pickle'
[INFO] 09:36: Evaluating PPO_third_experimentCartPole-v1...
[INFO] Evaluation:Moviepy - Building video <yourPath>/CartPole-v1-episode-0.mp4.
Moviepy - Writing video <yourPath>CartPole-v1-episode-0.mp4
Moviepy - Done !
Moviepy - video ready <yourPath>/CartPole-v1-episode-0.mp4
.Moviepy - Building video <yourPath>/CartPole-v1-episode-1.mp4.
Moviepy - Writing video <yourPath>/CartPole-v1-episode-1.mp4
Moviepy - Done !
Moviepy - video ready <yourPath>/CartPole-v1-episode-1.mp4
....... Evaluation finished
PPO_third_experimentCartPole-v1
0 500.0
1 500.0
2 500.0
3 500.0
4 500.0
5 500.0
6 500.0
7 500.0
8 500.0
9 500.0
10 500.0
11 500.0
12 500.0
13 500.0
14 500.0
Some advanced settings¶
Now an example with some more settings. (check the API to see all of them)
from rlberry.envs import gym_make
from rlberry.agents.stable_baselines import StableBaselinesAgent
from stable_baselines3 import PPO
from rlberry.manager import ExperimentManager, evaluate_agents
env_id = "CartPole-v1"
env_ctor = gym_make
env_kwargs = dict(id=env_id)
fourth_experiment = ExperimentManager(
StableBaselinesAgent, # Agent Class
train_env=(env_ctor, env_kwargs), # Environment to train the Agent
fit_budget=int(15000), # Budget used to call our agent "fit()"
eval_env=(
env_ctor,
env_kwargs,
), # Environment to eval the Agent (here, same as training env)
init_kwargs=dict(
algo_cls=PPO, batch_size=24, n_steps=96, device="cpu"
), # Agent setting
eval_kwargs=dict(
eval_horizon=1000
), # Arguments required to call rlberry.agents.agent.Agent.eval().
agent_name="PPO_fourth_experiment" + env_id, # Name of the agent
n_fit=4, # Number of agent instances to fit.
output_dir="./fourth_experiment_results/", # Directory where to store data.
parallelization="thread", # parallelize agent training using threads
max_workers=2, # max 2 threads with parallelization
enable_tensorboard=True, # enable tensorboard logging
)
fourth_experiment.fit()
output = evaluate_agents(
[fourth_experiment], n_simulations=5, plot=False
) # evaluate the experiment on 5 simulations
print(output)
[INFO] 09:45: Running ExperimentManager fit() for PPO_second_experimentCartPole-v1 with n_fit = 4 and max_workers = 2.
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 1440 | time/iterations = 14 | rollout/ep_rew_mean = 30.86046511627907 | rollout/ep_len_mean = 30.86046511627907 | time/fps = 497 | time/time_elapsed = 2 | time/total_timesteps = 1344 | train/learning_rate = 0.0003 | train/entropy_loss = -0.6368376821279526 | train/policy_gradient_loss = -0.0030540588200588916 | train/value_loss = 52.8653003692627 | train/approx_kl = 0.0012531293323263526 | train/clip_fraction = 0.0 | train/loss = 20.012786865234375 | train/explained_variance = 0.270730197429657 | train/n_updates = 130 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 1536 | time/iterations = 15 | rollout/ep_rew_mean = 39.22857142857143 | rollout/ep_len_mean = 39.22857142857143 | time/fps = 502 | time/time_elapsed = 2 | time/total_timesteps = 1440 | train/learning_rate = 0.0003 | train/entropy_loss = -0.618910662829876 | train/policy_gradient_loss = -0.007122196507649825 | train/value_loss = 124.85383853912353 | train/approx_kl = 0.004074861295521259 | train/clip_fraction = 0.009375000186264516 | train/loss = 58.4535026550293 | train/explained_variance = -0.02206575870513916 | train/n_updates = 140 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 2976 | time/iterations = 30 | rollout/ep_rew_mean = 49.49090909090909 | rollout/ep_len_mean = 49.49090909090909 | time/fps = 502 | time/time_elapsed = 5 | time/total_timesteps = 2880 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5889034822583199 | train/policy_gradient_loss = -0.010608512769977096 | train/value_loss = 84.22348279953003 | train/approx_kl = 0.004636458586901426 | train/clip_fraction = 0.06354166707023978 | train/loss = 37.387840270996094 | train/explained_variance = 0.16999149322509766 | train/n_updates = 290 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 3072 | time/iterations = 31 | rollout/ep_rew_mean = 59.18 | rollout/ep_len_mean = 59.18 | time/fps = 510 | time/time_elapsed = 5 | time/total_timesteps = 2976 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5197424411773681 | train/policy_gradient_loss = -0.00876332552181035 | train/value_loss = 89.44287853240967 | train/approx_kl = 0.0023070008028298616 | train/clip_fraction = 0.0 | train/loss = 27.723819732666016 | train/explained_variance = 0.12456077337265015 | train/n_updates = 300 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 4416 | time/iterations = 45 | rollout/ep_rew_mean = 66.71428571428571 | rollout/ep_len_mean = 66.71428571428571 | time/fps = 490 | time/time_elapsed = 8 | time/total_timesteps = 4320 | train/learning_rate = 0.0003 | train/entropy_loss = -0.6150185167789459 | train/policy_gradient_loss = -0.011918687870623534 | train/value_loss = 62.91612710952759 | train/approx_kl = 0.012545783072710037 | train/clip_fraction = 0.07500000055879355 | train/loss = 30.261075973510742 | train/explained_variance = 0.5195063650608063 | train/n_updates = 440 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 4416 | time/iterations = 45 | rollout/ep_rew_mean = 76.05357142857143 | rollout/ep_len_mean = 76.05357142857143 | time/fps = 484 | time/time_elapsed = 8 | time/total_timesteps = 4320 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5382911033928395 | train/policy_gradient_loss = -0.01824581954351743 | train/value_loss = 34.797289085388186 | train/approx_kl = 0.009921143762767315 | train/clip_fraction = 0.11458333358168601 | train/loss = 16.537925720214844 | train/explained_variance = 0.77537801861763 | train/n_updates = 440 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 5760 | time/iterations = 59 | rollout/ep_rew_mean = 80.8 | rollout/ep_len_mean = 80.8 | time/fps = 475 | time/time_elapsed = 11 | time/total_timesteps = 5664 | train/learning_rate = 0.0003 | train/entropy_loss = -0.6097852572798729 | train/policy_gradient_loss = -0.005027322360729158 | train/value_loss = 49.29339656829834 | train/approx_kl = 0.0017487265868112445 | train/clip_fraction = 0.0 | train/loss = 21.345821380615234 | train/explained_variance = 0.14309996366500854 | train/n_updates = 580 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 5856 | time/iterations = 60 | rollout/ep_rew_mean = 81.72058823529412 | rollout/ep_len_mean = 81.72058823529412 | time/fps = 473 | time/time_elapsed = 12 | time/total_timesteps = 5760 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5608772337436676 | train/policy_gradient_loss = -0.000609715585354298 | train/value_loss = 47.05806636810303 | train/approx_kl = 0.0004261930880602449 | train/clip_fraction = 0.0 | train/loss = 22.013322830200195 | train/explained_variance = 0.13966631889343262 | train/n_updates = 590 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 7296 | time/iterations = 75 | rollout/ep_rew_mean = 93.27631578947368 | rollout/ep_len_mean = 93.27631578947368 | time/fps = 479 | time/time_elapsed = 15 | time/total_timesteps = 7200 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5558830961585045 | train/policy_gradient_loss = -0.0035663537412043756 | train/value_loss = 57.799719190597536 | train/approx_kl = 0.010704685002565384 | train/clip_fraction = 0.026041666883975266 | train/loss = 24.911317825317383 | train/explained_variance = 0.7546885907649994 | train/n_updates = 740 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 7488 | time/iterations = 77 | rollout/ep_rew_mean = 95.78378378378379 | rollout/ep_len_mean = 95.78378378378379 | time/fps = 481 | time/time_elapsed = 15 | time/total_timesteps = 7392 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5342976003885269 | train/policy_gradient_loss = -0.003940091139186919 | train/value_loss = 29.248546028137206 | train/approx_kl = 0.0034270065370947123 | train/clip_fraction = 0.006250000186264515 | train/loss = 11.23060417175293 | train/explained_variance = 0.000810086727142334 | train/n_updates = 760 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 8832 | time/iterations = 91 | rollout/ep_rew_mean = 94.8021978021978 | rollout/ep_len_mean = 94.8021978021978 | time/fps = 483 | time/time_elapsed = 18 | time/total_timesteps = 8736 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5868215769529342 | train/policy_gradient_loss = -0.003875821301941573 | train/value_loss = 15.918508291244507 | train/approx_kl = 0.003322127740830183 | train/clip_fraction = 0.01250000037252903 | train/loss = 5.372678279876709 | train/explained_variance = 0.9379729703068733 | train/n_updates = 900 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 8928 | time/iterations = 92 | rollout/ep_rew_mean = 110.62025316455696 | rollout/ep_len_mean = 110.62025316455696 | time/fps = 477 | time/time_elapsed = 18 | time/total_timesteps = 8832 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5886116042733193 | train/policy_gradient_loss = -0.0061642722316454625 | train/value_loss = 7.651307249069214 | train/approx_kl = 0.00532135833054781 | train/clip_fraction = 0.02083333395421505 | train/loss = 2.704312801361084 | train/explained_variance = 0.9291621446609497 | train/n_updates = 910 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 10272 | time/iterations = 106 | rollout/ep_rew_mean = 102.26530612244898 | rollout/ep_len_mean = 102.26530612244898 | time/fps = 481 | time/time_elapsed = 21 | time/total_timesteps = 10176 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5608879745006561 | train/policy_gradient_loss = -0.00618959182217318 | train/value_loss = 341.5462481498718 | train/approx_kl = 0.002049457747489214 | train/clip_fraction = 0.0 | train/loss = 115.31817626953125 | train/explained_variance = 0.03178894519805908 | train/n_updates = 1050 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 10464 | time/iterations = 108 | rollout/ep_rew_mean = 120.68235294117648 | rollout/ep_len_mean = 120.68235294117648 | time/fps = 480 | time/time_elapsed = 21 | time/total_timesteps = 10368 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5731720849871635 | train/policy_gradient_loss = -0.008771563362703683 | train/value_loss = 809.6955997467041 | train/approx_kl = 0.004173839930444956 | train/clip_fraction = 0.018750000465661287 | train/loss = 382.14801025390625 | train/explained_variance = 0.0032292604446411133 | train/n_updates = 1070 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 11616 | time/iterations = 120 | rollout/ep_rew_mean = 113.77 | rollout/ep_len_mean = 113.77 | time/fps = 474 | time/time_elapsed = 24 | time/total_timesteps = 11520 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5582666076719761 | train/policy_gradient_loss = -0.006921725869559215 | train/value_loss = 403.52278537750243 | train/approx_kl = 0.002198959467932582 | train/clip_fraction = 0.0 | train/loss = 240.1759490966797 | train/explained_variance = -0.19455385208129883 | train/n_updates = 1190 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 11808 | time/iterations = 122 | rollout/ep_rew_mean = 129.01111111111112 | rollout/ep_len_mean = 129.01111111111112 | time/fps = 473 | time/time_elapsed = 24 | time/total_timesteps = 11712 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5791081696748733 | train/policy_gradient_loss = 0.0027768491202399214 | train/value_loss = 579.2247428894043 | train/approx_kl = 0.0006394482916221023 | train/clip_fraction = 0.0 | train/loss = 108.69767761230469 | train/explained_variance = -0.7034773826599121 | train/n_updates = 1210 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 12864 | time/iterations = 133 | rollout/ep_rew_mean = 122.84 | rollout/ep_len_mean = 122.84 | time/fps = 467 | time/time_elapsed = 27 | time/total_timesteps = 12768 | train/learning_rate = 0.0003 | train/entropy_loss = -0.585125806927681 | train/policy_gradient_loss = -0.0028700591409382527 | train/value_loss = 17.194953203201294 | train/approx_kl = 0.007809734903275967 | train/clip_fraction = 0.015625000279396773 | train/loss = 7.225722789764404 | train/explained_variance = -0.04570794105529785 | train/n_updates = 1320 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 13152 | time/iterations = 136 | rollout/ep_rew_mean = 137.4516129032258 | rollout/ep_len_mean = 137.4516129032258 | time/fps = 467 | time/time_elapsed = 27 | time/total_timesteps = 13056 | train/learning_rate = 0.0003 | train/entropy_loss = -0.566350145637989 | train/policy_gradient_loss = -0.004751363794999452 | train/value_loss = 31.131759536266326 | train/approx_kl = 0.0031535024754703045 | train/clip_fraction = 0.002083333395421505 | train/loss = 3.930537462234497 | train/explained_variance = 0.9139308258891106 | train/n_updates = 1350 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 0]] | max_global_step = 14112 | time/iterations = 146 | rollout/ep_rew_mean = 136.14 | rollout/ep_len_mean = 136.14 | time/fps = 458 | time/time_elapsed = 30 | time/total_timesteps = 14016 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5963118925690651 | train/policy_gradient_loss = -0.007955966270916815 | train/value_loss = 9.367142927646636 | train/approx_kl = 0.010106074623763561 | train/clip_fraction = 0.07291666744276881 | train/loss = 3.582631826400757 | train/explained_variance = 0.14140963554382324 | train/n_updates = 1450 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 1]] | max_global_step = 14304 | time/iterations = 148 | rollout/ep_rew_mean = 145.38144329896906 | rollout/ep_len_mean = 145.38144329896906 | time/fps = 457 | time/time_elapsed = 31 | time/total_timesteps = 14208 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5282964281737804 | train/policy_gradient_loss = -0.0037513579605426006 | train/value_loss = 0.7543770960532129 | train/approx_kl = 0.003314702305942774 | train/clip_fraction = 0.04687500018626452 | train/loss = 0.028775174170732498 | train/explained_variance = 0.9980020457878709 | train/n_updates = 1470 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 1344 | time/iterations = 13 | rollout/ep_rew_mean = 30.974358974358974 | rollout/ep_len_mean = 30.974358974358974 | time/fps = 429 | time/time_elapsed = 2 | time/total_timesteps = 1248 | train/learning_rate = 0.0003 | train/entropy_loss = -0.6186478942632675 | train/policy_gradient_loss = -0.01541837720311987 | train/value_loss = 59.90045881271362 | train/approx_kl = 0.008347732946276665 | train/clip_fraction = 0.05625000074505806 | train/loss = 25.35782241821289 | train/explained_variance = -0.03064143657684326 | train/n_updates = 120 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 1344 | time/iterations = 13 | rollout/ep_rew_mean = 32.27777777777778 | rollout/ep_len_mean = 32.27777777777778 | time/fps = 420 | time/time_elapsed = 2 | time/total_timesteps = 1248 | train/learning_rate = 0.0003 | train/entropy_loss = -0.6108133271336555 | train/policy_gradient_loss = -0.005322299412182474 | train/value_loss = 101.77589092254638 | train/approx_kl = 0.0019470953848212957 | train/clip_fraction = 0.0010416666977107526 | train/loss = 40.62103271484375 | train/explained_variance = 0.07671612501144409 | train/n_updates = 120 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 2592 | time/iterations = 26 | rollout/ep_rew_mean = 50.791666666666664 | rollout/ep_len_mean = 50.791666666666664 | time/fps = 421 | time/time_elapsed = 5 | time/total_timesteps = 2496 | train/learning_rate = 0.0003 | train/entropy_loss = -0.6129413187503815 | train/policy_gradient_loss = -0.0026073096491330714 | train/value_loss = 99.97837677001954 | train/approx_kl = 0.0008606038172729313 | train/clip_fraction = 0.0 | train/loss = 44.147621154785156 | train/explained_variance = 0.07078427076339722 | train/n_updates = 250 | train/clip_range = 0.2 |
[INFO] 09:45: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 2784 | time/iterations = 28 | rollout/ep_rew_mean = 49.5 | rollout/ep_len_mean = 49.5 | time/fps = 433 | time/time_elapsed = 6 | time/total_timesteps = 2688 | train/learning_rate = 0.0003 | train/entropy_loss = -0.585808028280735 | train/policy_gradient_loss = -0.000618002787662908 | train/value_loss = 95.70521297454835 | train/approx_kl = 0.0011669064406305552 | train/clip_fraction = 0.0 | train/loss = 70.0313491821289 | train/explained_variance = 0.03644925355911255 | train/n_updates = 270 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 3936 | time/iterations = 40 | rollout/ep_rew_mean = 63.172413793103445 | rollout/ep_len_mean = 63.172413793103445 | time/fps = 426 | time/time_elapsed = 9 | time/total_timesteps = 3840 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5633251592516899 | train/policy_gradient_loss = -0.009321122000134574 | train/value_loss = 147.42370948791503 | train/approx_kl = 0.004084523767232895 | train/clip_fraction = 0.025000000558793544 | train/loss = 58.39215087890625 | train/explained_variance = 0.008745789527893066 | train/n_updates = 390 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 4224 | time/iterations = 43 | rollout/ep_rew_mean = 63.49230769230769 | rollout/ep_len_mean = 63.49230769230769 | time/fps = 442 | time/time_elapsed = 9 | time/total_timesteps = 4128 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5803879588842392 | train/policy_gradient_loss = -0.014389420735763759 | train/value_loss = 104.66002407073975 | train/approx_kl = 0.004097627475857735 | train/clip_fraction = 0.0406250006519258 | train/loss = 36.91357421875 | train/explained_variance = 0.06607359647750854 | train/n_updates = 420 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 5376 | time/iterations = 55 | rollout/ep_rew_mean = 77.64179104477611 | rollout/ep_len_mean = 77.64179104477611 | time/fps = 436 | time/time_elapsed = 12 | time/total_timesteps = 5280 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5912896677851677 | train/policy_gradient_loss = -0.005140897812877121 | train/value_loss = 51.03294086456299 | train/approx_kl = 0.0011872043833136559 | train/clip_fraction = 0.0010416666977107526 | train/loss = 22.535093307495117 | train/explained_variance = -0.058519959449768066 | train/n_updates = 540 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 5568 | time/iterations = 57 | rollout/ep_rew_mean = 70.6103896103896 | rollout/ep_len_mean = 70.6103896103896 | time/fps = 442 | time/time_elapsed = 12 | time/total_timesteps = 5472 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5753983780741692 | train/policy_gradient_loss = -0.007284667211085139 | train/value_loss = 139.77001705169678 | train/approx_kl = 0.006244419142603874 | train/clip_fraction = 0.018750000558793545 | train/loss = 27.275583267211914 | train/explained_variance = -0.08379793167114258 | train/n_updates = 560 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 6816 | time/iterations = 70 | rollout/ep_rew_mean = 91.43835616438356 | rollout/ep_len_mean = 91.43835616438356 | time/fps = 444 | time/time_elapsed = 15 | time/total_timesteps = 6720 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5323616154491901 | train/policy_gradient_loss = -0.007125963812965574 | train/value_loss = 24.626363372802736 | train/approx_kl = 0.006300304085016251 | train/clip_fraction = 0.037500000651925804 | train/loss = 13.018963813781738 | train/explained_variance = 0.9616018049418926 | train/n_updates = 690 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 7104 | time/iterations = 73 | rollout/ep_rew_mean = 77.64044943820225 | rollout/ep_len_mean = 77.64044943820225 | time/fps = 452 | time/time_elapsed = 15 | time/total_timesteps = 7008 | train/learning_rate = 0.0003 | train/entropy_loss = -0.6117519900202751 | train/policy_gradient_loss = -0.00272596117890016 | train/value_loss = 280.87690296173093 | train/approx_kl = 0.0006742061232216656 | train/clip_fraction = 0.0 | train/loss = 177.05584716796875 | train/explained_variance = 0.23516911268234253 | train/n_updates = 720 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 8160 | time/iterations = 84 | rollout/ep_rew_mean = 96.7710843373494 | rollout/ep_len_mean = 96.7710843373494 | time/fps = 439 | time/time_elapsed = 18 | time/total_timesteps = 8064 | train/learning_rate = 0.0003 | train/entropy_loss = -0.57562275826931 | train/policy_gradient_loss = -0.007087657243634205 | train/value_loss = 10.132426935434342 | train/approx_kl = 0.006503245793282986 | train/clip_fraction = 0.013541666883975267 | train/loss = 1.0611423254013062 | train/explained_variance = 0.9250432252883911 | train/n_updates = 830 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 8352 | time/iterations = 86 | rollout/ep_rew_mean = 83.17171717171718 | rollout/ep_len_mean = 83.17171717171718 | time/fps = 441 | time/time_elapsed = 18 | time/total_timesteps = 8256 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5499906323850154 | train/policy_gradient_loss = -0.006553472934062299 | train/value_loss = 26.234399175643922 | train/approx_kl = 0.0049788737669587135 | train/clip_fraction = 0.01979166707023978 | train/loss = 8.909204483032227 | train/explained_variance = 0.6594350934028625 | train/n_updates = 850 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 9600 | time/iterations = 99 | rollout/ep_rew_mean = 107.0 | rollout/ep_len_mean = 107.0 | time/fps = 442 | time/time_elapsed = 21 | time/total_timesteps = 9504 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5261909484863281 | train/policy_gradient_loss = -0.0017483091195268584 | train/value_loss = 11.570764398574829 | train/approx_kl = 0.003514515236020088 | train/clip_fraction = 0.002083333395421505 | train/loss = 4.586752414703369 | train/explained_variance = -0.13919365406036377 | train/n_updates = 980 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 9792 | time/iterations = 101 | rollout/ep_rew_mean = 94.67 | rollout/ep_len_mean = 94.67 | time/fps = 447 | time/time_elapsed = 21 | time/total_timesteps = 9696 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5318385265767575 | train/policy_gradient_loss = -0.011880275755174807 | train/value_loss = 6.452494937181473 | train/approx_kl = 0.005105054937303066 | train/clip_fraction = 0.026041667256504298 | train/loss = 1.5928417444229126 | train/explained_variance = 0.9581267684698105 | train/n_updates = 1000 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 11136 | time/iterations = 115 | rollout/ep_rew_mean = 119.93406593406593 | rollout/ep_len_mean = 119.93406593406593 | time/fps = 450 | time/time_elapsed = 24 | time/total_timesteps = 11040 | train/learning_rate = 0.0003 | train/entropy_loss = -0.597024767100811 | train/policy_gradient_loss = 0.0026963132240780396 | train/value_loss = 113.00028538703918 | train/approx_kl = 0.00123556365724653 | train/clip_fraction = 0.0 | train/loss = 37.44751739501953 | train/explained_variance = 0.7172763645648956 | train/n_updates = 1140 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 11232 | time/iterations = 116 | rollout/ep_rew_mean = 107.57 | rollout/ep_len_mean = 107.57 | time/fps = 449 | time/time_elapsed = 24 | time/total_timesteps = 11136 | train/learning_rate = 0.0003 | train/entropy_loss = -0.5200830087065696 | train/policy_gradient_loss = -0.007722906641962868 | train/value_loss = 14.537515223026276 | train/approx_kl = 0.007102598436176777 | train/clip_fraction = 0.09479166679084301 | train/loss = 2.2106761932373047 | train/explained_variance = 0.3601408004760742 | train/n_updates = 1150 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 12672 | time/iterations = 131 | rollout/ep_rew_mean = 129.17021276595744 | rollout/ep_len_mean = 129.17021276595744 | time/fps = 454 | time/time_elapsed = 27 | time/total_timesteps = 12576 | train/learning_rate = 0.0003 | train/entropy_loss = -0.4788337767124176 | train/policy_gradient_loss = -0.038107051831805926 | train/value_loss = 0.19971267301589252 | train/approx_kl = 0.03344881534576416 | train/clip_fraction = 0.4125000021420419 | train/loss = -0.027751892805099487 | train/explained_variance = 0.9155157506465912 | train/n_updates = 1300 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 12672 | time/iterations = 131 | rollout/ep_rew_mean = 120.55 | rollout/ep_len_mean = 120.55 | time/fps = 451 | time/time_elapsed = 27 | time/total_timesteps = 12576 | train/learning_rate = 0.0003 | train/entropy_loss = -0.43379202783107756 | train/policy_gradient_loss = 0.0009571537776840389 | train/value_loss = 1.2258590620011092 | train/approx_kl = 0.00857666414231062 | train/clip_fraction = 0.02291666679084301 | train/loss = 0.1831377148628235 | train/explained_variance = 0.9741729144006968 | train/n_updates = 1300 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 13824 | time/iterations = 143 | rollout/ep_rew_mean = 138.340206185567 | rollout/ep_len_mean = 138.340206185567 | time/fps = 448 | time/time_elapsed = 30 | time/total_timesteps = 13728 | train/learning_rate = 0.0003 | train/entropy_loss = -0.644160869717598 | train/policy_gradient_loss = -0.008214838248265188 | train/value_loss = 0.01987018278450705 | train/approx_kl = 0.013853602111339569 | train/clip_fraction = 0.051041666977107526 | train/loss = -0.009712214581668377 | train/explained_variance = -0.004491209983825684 | train/n_updates = 1420 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 13824 | time/iterations = 143 | rollout/ep_rew_mean = 131.25 | rollout/ep_len_mean = 131.25 | time/fps = 446 | time/time_elapsed = 30 | time/total_timesteps = 13728 | train/learning_rate = 0.0003 | train/entropy_loss = -0.49214922785758974 | train/policy_gradient_loss = -0.0010527112196238697 | train/value_loss = 7.321832603216171 | train/approx_kl = 0.0050249057821929455 | train/clip_fraction = 0.05833333460614085 | train/loss = 1.8884248733520508 | train/explained_variance = 0.7490366697311401 | train/n_updates = 1420 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 2]] | max_global_step = 14976 | time/iterations = 155 | rollout/ep_rew_mean = 147.17 | rollout/ep_len_mean = 147.17 | time/fps = 440 | time/time_elapsed = 33 | time/total_timesteps = 14880 | train/learning_rate = 0.0003 | train/entropy_loss = -0.564744371175766 | train/policy_gradient_loss = -0.00030555504467870697 | train/value_loss = 583.7946674346924 | train/approx_kl = 5.618979685095837e-06 | train/clip_fraction = 0.0 | train/loss = 178.1756591796875 | train/explained_variance = 0.13469618558883667 | train/n_updates = 1540 | train/clip_range = 0.2 |
[INFO] 09:46: [PPO_second_experimentCartPole-v1[worker: 3]] | max_global_step = 14976 | time/iterations = 155 | rollout/ep_rew_mean = 139.76 | rollout/ep_len_mean = 139.76 | time/fps = 436 | time/time_elapsed = 34 | time/total_timesteps = 14880 | train/learning_rate = 0.0003 | train/entropy_loss = -0.48720408231019974 | train/policy_gradient_loss = -0.004510738217747256 | train/value_loss = 0.15749059994705022 | train/approx_kl = 0.00864747166633606 | train/clip_fraction = 0.051041667256504296 | train/loss = 0.0023154467344284058 | train/explained_variance = -0.05674338340759277 | train/n_updates = 1540 | train/clip_range = 0.2 |
[INFO] 09:46: ... trained!
[INFO] 09:46: Saved ExperimentManager(PPO_second_experimentCartPole-v1) using pickle.
[INFO] 09:46: The ExperimentManager was saved in : 'fourth_experiment_results/manager_data/PPO_second_experimentCartPole-v1_2024-04-12_09-45-19_3d4e7443/manager_obj.pickle'
[INFO] 09:46: Evaluating PPO_second_experimentCartPole-v1...
[INFO] Evaluation:..... Evaluation finished
PPO_fourth_experimentCartPole-v1
0 500.0
1 500.0
2 500.0
3 500.0
4 500.0
In the output you can see the learning of the workers 0 and 1 first, then 2 and 3 (4 fit, but max 2 threads with parallelization).
You can check the tensorboard logging with
tensorboard --logdir <path to your output_dir>.
Other information¶
Be careful, if you use a torch agent with the rlberry’s ExperimentManager, the “torch seed” will be set for you (if you have specify the seed in the ExperimentManager parameters). More information about the seeding in rlberry here.