An RL Library for Research and Education¶
Writing reinforcement learning algorithms is fun! But after the fun, we have lots of boring things to implement: run our agents in parallel, average and plot results, optimize hyperparameters, compare to baselines, create tricky environments etc etc!
rlberry is here to make your life easier by doing all these things with a few lines of code, so that you can spend most of your time developing agents.
We provide you a number of tools to help you achieve reproducibility, statistically comparisons of RL agents, and nice visualization.
If you begin with rlberry, check our RL quickstart and our Deep RL quickstart.
Tools designed to facilitate RL experimentation.
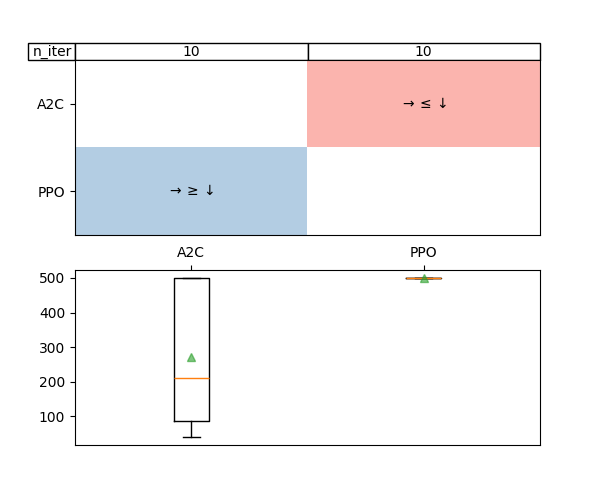
Statistical tools for agent comparison.
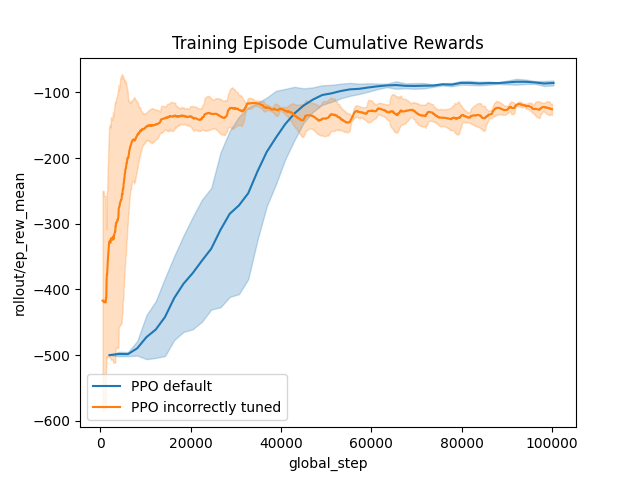
Proper smoothing and plot of confidence intervals.
Simple environments and tools for use in teaching RL.

Code is easy to read and easy to change.

Uses stable-baselines, tensorboard, gymnasium, and you can easily write your wrapper to use your own RL library. Visualization and statistical tool can be used with dataframes as input/output in order to be library-independent.
Documentation Contents¶
You can find main documentation here :
Contributing to rlberry¶
If you want to contribute to rlberry, check out the contribution guidelines.
rlberry main features¶
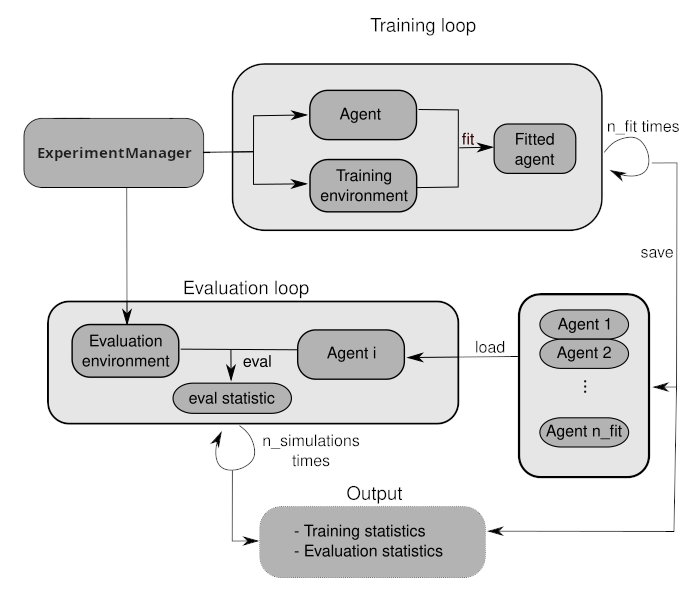
ExperimentManager¶
This is one of the core element in rlberry. The ExperimentManager allow you to easily make an experiment between an Agent and an Environment. It’s use to train, optimize hyperparameters, evaluate and gather statistics about an agent. See the ExperimentManager page.
Seeding & Reproducibility¶
rlberry has a class Seeder that conveniently wraps a NumPy SeedSequence, and allows us to create independent random number generators for different objects and threads, using a single Seeder instance. See the Seeding page.
You can also save and load your experiments. It could be useful in many way :
don’t repeat the training part every time.
continue a previous training (or doing checkpoint).
See the Save and Load Experiment page.
Statistical comparison of RL agents¶
The principal goal of rlberry is to give tools for proper experimentations in RL. In research, one of the usual tasks is to compare two or more RL agents, and for this one typically uses several seeds to train the agents several times and compare the resulting mean reward. We show here how to make sure that enough data and enough information were acquired to assert that two RL agents are indeed different. We propose two ways to do that: first are classical hypothesis testing and second are sequential testing scheme with AdaStop that aim at saving computation by stopping early if possible.
Compare agents¶
We give tools to compare several trained agents using the mean over a specify number of evaluations for each agent. The explanation can be found in the user guide.
AdaStop¶
AdaStop is a Sequential testing for efficient and reliable comparison of stochastic algorithms. It has been successfully used to compare efficiently RL agents and an example of such use can be found in the user guide.
Visualization¶
TODO :
And many more !¶
Check the User Guide to find more tools !