Note
Go to the end to download the full example code
Comparison of Thompson sampling and UCB on Bernoulli and Gaussian bandits¶
This script shows how to use Thompson sampling on two examples: Bernoulli and Gaussian bandits.
In the Bernoulli case, we use Thompson sampling with a Beta prior. We compare it to a UCB for bounded rewards with support in [0,1]. For the Gaussian case, we use a Gaussian prior and compare it to a sub-Gaussian UCB.
[INFO] 13:51: ... trained!
[INFO] 13:51: Saved ExperimentManager(Bounded UCB Agent) using pickle.
[INFO] 13:51: The ExperimentManager was saved in : 'rlberry_data/temp/manager_data/Bounded UCB Agent_2025-04-30_13-51-01_3f655797/manager_obj.pickle'
[INFO] 13:51: Running ExperimentManager fit() for Bernoulli TS Agent with n_fit = 10 and max_workers = None.
[INFO] 13:51: ... trained!
[INFO] 13:51: Saved ExperimentManager(Bernoulli TS Agent) using pickle.
[INFO] 13:51: The ExperimentManager was saved in : 'rlberry_data/temp/manager_data/Bernoulli TS Agent_2025-04-30_13-51-01_901ee062/manager_obj.pickle'
[INFO] 13:51: Running ExperimentManager fit() for Gaussian UCB Agent with n_fit = 10 and max_workers = None.
[INFO] 13:51: ... trained!
[INFO] 13:51: Saved ExperimentManager(Gaussian UCB Agent) using pickle.
[INFO] 13:51: The ExperimentManager was saved in : 'rlberry_data/temp/manager_data/Gaussian UCB Agent_2025-04-30_13-51-11_4f678a9e/manager_obj.pickle'
[INFO] 13:51: Running ExperimentManager fit() for Gaussian TS Agent with n_fit = 10 and max_workers = None.
[INFO] 13:51: ... trained!
[INFO] 13:51: Saved ExperimentManager(Gaussian TS Agent) using pickle.
[INFO] 13:51: The ExperimentManager was saved in : 'rlberry_data/temp/manager_data/Gaussian TS Agent_2025-04-30_13-51-11_74ba2a5c/manager_obj.pickle'
import numpy as np
from rlberry_research.envs.bandits import BernoulliBandit, NormalBandit
from rlberry_research.agents.bandits import (
IndexAgent,
TSAgent,
makeBoundedUCBIndex,
makeSubgaussianUCBIndex,
makeBetaPrior,
makeGaussianPrior,
)
from rlberry.manager import ExperimentManager, plot_writer_data
# Bernoulli
# Agents definition
class BernoulliTSAgent(TSAgent):
"""Thompson sampling for Bernoulli bandit"""
name = "Bernoulli TS Agent"
def __init__(self, env, **kwargs):
prior, _ = makeBetaPrior()
TSAgent.__init__(self, env, prior, writer_extra="action", **kwargs)
class BoundedUCBAgent(IndexAgent):
"""UCB agent for bounded bandits"""
name = "Bounded UCB Agent"
def __init__(self, env, **kwargs):
index, _ = makeBoundedUCBIndex(0, 1)
IndexAgent.__init__(self, env, index, writer_extra="action", **kwargs)
# Parameters of the problem
means = np.array([0.8, 0.8, 0.9, 1]) # means of the arms
A = len(means)
T = 2000 # Horizon
M = 10 # number of MC simu
# Construction of the experiment
env_ctor = BernoulliBandit
env_kwargs = {"p": means}
agents = [
ExperimentManager(
Agent,
(env_ctor, env_kwargs),
fit_budget=T,
n_fit=M,
)
for Agent in [BoundedUCBAgent, BernoulliTSAgent]
]
# Agent training
for agent in agents:
agent.fit()
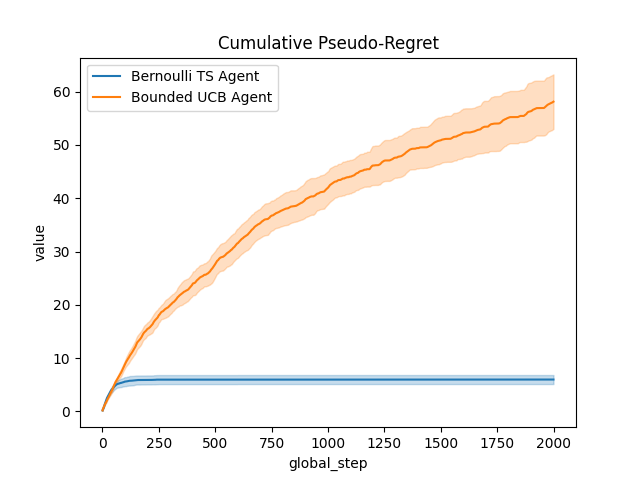
# Compute and plot (pseudo-)regret
def compute_pseudo_regret(actions):
return np.cumsum(np.max(means) - means[actions.astype(int)])
output = plot_writer_data(
agents,
tag="action",
preprocess_func=compute_pseudo_regret,
title="Cumulative Pseudo-Regret",
)
# Gaussian
class GaussianTSAgent(TSAgent):
"""Thompson sampling for Gaussian bandit"""
name = "Gaussian TS Agent"
def __init__(self, env, sigma=1.0, **kwargs):
prior, _ = makeGaussianPrior(sigma)
TSAgent.__init__(self, env, prior, writer_extra="action", **kwargs)
class GaussianUCBAgent(IndexAgent):
"""UCB agent for Gaussian bandits"""
name = "Gaussian UCB Agent"
def __init__(self, env, sigma=1.0, **kwargs):
index, _ = makeSubgaussianUCBIndex(sigma)
IndexAgent.__init__(self, env, index, writer_extra="action", **kwargs)
# Parameters of the problem
means = np.array([0.3, 0.5]) # means of the arms
sigma = 1.0 # means of the arms
A = len(means)
T = 2000 # Horizon
M = 10 # number of MC simu
# Construction of the experiment
env_ctor = NormalBandit
env_kwargs = {"means": means, "stds": sigma * np.ones(A)}
agents = [
ExperimentManager(
Agent,
(env_ctor, env_kwargs),
fit_budget=T,
n_fit=M,
)
for Agent in [GaussianUCBAgent, GaussianTSAgent]
]
# Agent training
for agent in agents:
agent.fit()
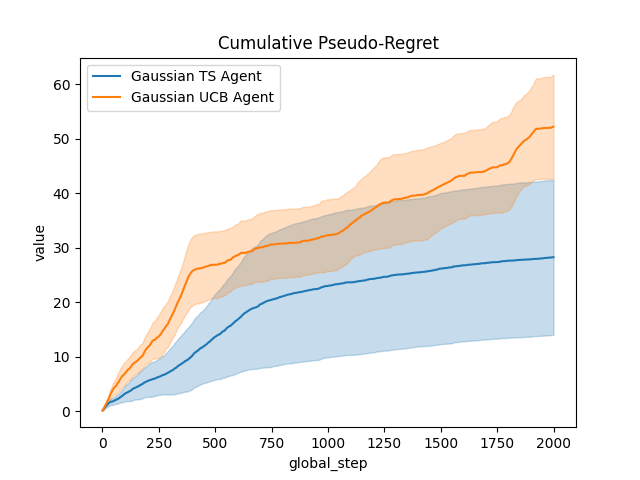
# Compute and plot (pseudo-)regret
def compute_pseudo_regret(actions):
return np.cumsum(np.max(means) - means[actions.astype(int)])
output = plot_writer_data(
agents,
tag="action",
preprocess_func=compute_pseudo_regret,
title="Cumulative Pseudo-Regret",
)
Total running time of the script: (0 minutes 18.908 seconds)