rlberry.agents.AgentWithSimplePolicy¶
- class rlberry.agents.AgentWithSimplePolicy(env: Env | Tuple[Callable[[...], Env], Mapping[str, Any]] | None = None, eval_env: Env | Tuple[Callable[[...], Env], Mapping[str, Any]] | None = None, copy_env: bool = True, compress_pickle: bool = True, seeder: Seeder | int | None = None, output_dir: str | None = None, writer_extra: str | None = None, _execution_metadata: ExecutionMetadata | None = None, _default_writer_kwargs: dict | None = None, _thread_shared_data: dict | None = None)[source]¶
Bases:
AgentInterface for agents whose policy is a function of observations only.
Requires a
policy()method, and a simple evaluation method (Monte-Carlo policy evaluation).The
policy()method takes an observation as input and returns an action.Note
1 - Abstract Class : cannot be instantiated. The abstract methods have to be Overwritten by the ‘inherited class’ agent.2 - Classes that implements this interface can send **kwargs to initiateAgent.__init__()(Agent), but the keys must match the parameters.- Parameters:
- envgymnasium.Env or tuple (constructor, kwargs)
Environment used to fit the agent.
- eval_envgymnasium.Env or tuple (constructor, kwargs)
Environment on which to evaluate the agent. If None, copied from env.
- copy_envbool
If true, makes a deep copy of the environment.
- compress_picklebool
If true, compress the save files using bz2.
- seeder
Seeder, int, or None Seeder/seed for random number generation.
- output_dirstr or Path
Directory that the agent can use to store data.
- _execution_metadataExecutionMetadata, optional
Extra information about agent execution (e.g. about which is the process id where the agent is running). Used by
ExperimentManager.- _default_writer_kwargsdict, optional
Parameters to initialize
DefaultWriter(attribute self.writer). Used byExperimentManager.- _thread_shared_datadict, optional
Used by
ExperimentManagerto share data across Agent instances created in different threads.- **kwargsdict
Classes that implement this interface must send
**kwargstoAgentWithSimplePolicy.__init__().
- Attributes:
- namestring
Agent identifier (not necessarily unique).
- env
gymnasium.Envor tuple (constructor, kwargs) Environment on which to train the agent.
- eval_env
gymnasium.Envor tuple (constructor, kwargs) Environment on which to evaluate the agent. If None, copied from env.
writerobject, default: NoneWriter object to log the output (e.g.
- seeder
Seeder, int, or None Seeder/seed for random number generation.
rngnumpy.random._generator.GeneratorRandom number generator.
output_dirstr or PathDirectory that the agent can use to store data.
unique_idstrUnique identifier for the agent instance.
thread_shared_datadictData shared by agent instances among different threads.
- writer_extra (through class Agent)str in {“reward”, “action”, “action_and_reward”},
Scalar that will be recorded in the writer.
Examples
>>> class RandomAgent(AgentWithSimplePolicy): >>> name = "RandomAgent" >>> >>> def __init__(self, env, **kwargs): >>> AgentWithSimplePolicy.__init__(self, env, **kwargs) >>> >>> def fit(self, budget=100, **kwargs): >>> observation,info = self.env.reset() >>> for ep in range(budget): >>> action = self.policy(observation) >>> observation, reward, terminated, truncated, info = self.env.step(action) >>> >>> def policy(self, observation): >>> return self.env.action_space.sample() # choose an action at random
Methods
eval([eval_horizon, n_simulations, gamma])Monte-Carlo policy evaluation [1] method to estimate the mean discounted reward using the current policy on the evaluation environment.
fit(budget, **kwargs)Abstract method to be overridden by the 'inherited agent'.
get_params([deep])Get parameters for this agent.
load(filename, **kwargs)Load agent object from filepath.
policy(observation)Abstract method.
reseed([seed_seq])Get new random number generator for the agent.
sample_parameters(trial)Sample hyperparameters for hyperparam optimization using Optuna (https://optuna.org/)
save(filename)Save agent object.
set_writer(writer)set self._writer.
- eval(eval_horizon=100000, n_simulations=10, gamma=1.0)[source]¶
Monte-Carlo policy evaluation [1] method to estimate the mean discounted reward using the current policy on the evaluation environment.
- Parameters:
- eval_horizonint, optional, default: 10**5
Maximum episode length, representing the horizon for each simulation.
- n_simulationsint, optional, default: 10
Number of Monte Carlo simulations to perform for the evaluation.
- gammafloat, optional, default: 1.0
Discount factor for future rewards.
- Returns:
- float
The mean value over ‘n_simulations’ of the sum of rewards obtained in each simulation.
References
- abstract fit(budget: int, **kwargs)¶
Abstract method to be overridden by the ‘inherited agent’.
Train the agent with a fixed budget, using the provided environment.
- Parameters:
- budget: int
Computational (or sample complexity) budget. It can be, for instance:
The number of timesteps taken by the environment (env.step) or the number of episodes;
The number of iterations for algorithms such as value/policy iteration;
The number of searches in MCTS (Monte-Carlo Tree Search) algorithms;
among others.
Ideally, calling
fit(budget1) fit(budget2)
should be equivalent to one call
fit(budget1 + budget2)
This property is required to reduce the time required for hyperparameter optimization (by allowing early stopping), but it is not strictly required elsewhere in the library.
If the agent does not require a budget, set it to -1.
- **kwargs: Keyword Arguments
Extra parameters specific to the implemented fit.
- get_params(deep=True)¶
Get parameters for this agent.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this agent and contained subobjects.
- Returns:
- paramsdict
Parameter names mapped to their values.
- classmethod load(filename, **kwargs)¶
Load agent object from filepath.
If overridden, save() method must also be overridden.
- Parameters:
- filename: str
Path to the object (pickle) to load.
- **kwargs: Keyword Arguments
Arguments required by the __init__ method of the Agent subclass to load.
- property output_dir¶
Directory that the agent can use to store data.
- abstract policy(observation)[source]¶
Abstract method. The policy function takes an observation from the environment and returns an action. The specific implementation of the policy function depends on the agent’s learning algorithm or strategy, which can be deterministic or stochastic. Parameters ———- observation (any): An observation from the environment. Returns ——- action (any): The action to be taken based on the provided observation. Notes —– The data type of ‘observation’ and ‘action’ can vary depending on the specific agent and the environment it interacts with.
- reseed(seed_seq=None)¶
Get new random number generator for the agent.
- Parameters:
- seed_seq
numpy.random.SeedSequence,rlberry.seeding.seeder.Seederor int, defaultNone Seed sequence from which to spawn the random number generator. If None, generate random seed. If int, use as entropy for SeedSequence. If seeder, use seeder.seed_seq
- seed_seq
- property rng¶
Random number generator.
- classmethod sample_parameters(trial)¶
Sample hyperparameters for hyperparam optimization using Optuna (https://optuna.org/)
Note: only the kwargs sent to __init__ are optimized. Make sure to include in the Agent constructor all “optimizable” parameters.
- Parameters:
- trial: optuna.trial
- save(filename)¶
Save agent object. By default, the agent is pickled.
If overridden, the load() method must also be overridden.
Before saving, consider setting writer to None if it can’t be pickled (tensorboard writers keep references to files and cannot be pickled).
Note: dill[R466db297bd20-1]_ is used when pickle fails (see https://stackoverflow.com/a/25353243, for instance). Pickle is tried first, since it is faster.
- Parameters:
- filename: Path or str
File in which to save the Agent.
- Returns:
- pathlib.Path
If save() is successful, a Path object corresponding to the filename is returned. Otherwise, None is returned.
Warning
The returned filename might differ from the input filename: For instance, ..
- the method can append the correct suffix to the name before saving.
References
- set_writer(writer)¶
set self._writer. If is not None, add parameters values to writer.
Data shared by agent instances among different threads.
- property unique_id¶
Unique identifier for the agent instance. Can be used, for example, to create files/directories for the agent to log data safely.
- property writer¶
Writer object to log the output (e.g. tensorboard SummaryWriter)..
Examples using rlberry.agents.AgentWithSimplePolicy¶
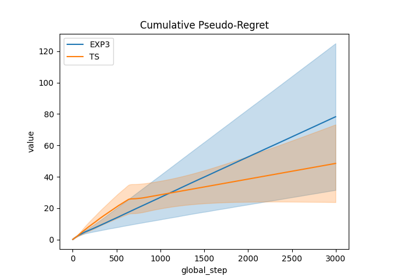
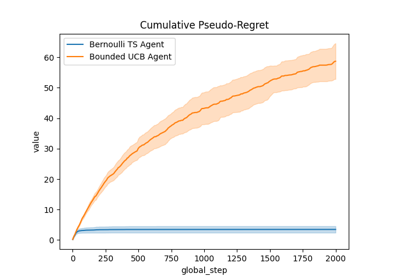
Comparison of Thompson sampling and UCB on Bernoulli and Gaussian bandits
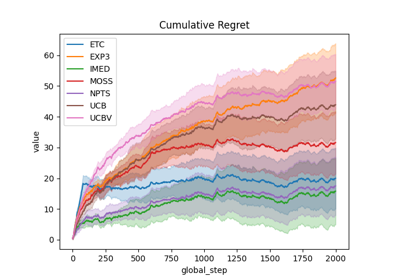
Comparison subplots of various index based bandits algorithms
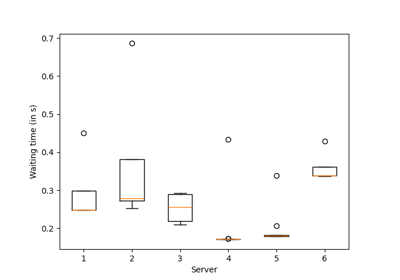
A demo of Bandit BAI on a real dataset to select mirrors