rlberry.manager.ExperimentManager¶
- class rlberry.manager.ExperimentManager(agent_class, train_env=(None, None), fit_budget=None, eval_env=None, init_kwargs=None, fit_kwargs=None, eval_kwargs=None, agent_name=None, n_fit=4, output_dir=None, parallelization='thread', max_workers=None, mp_context='spawn', worker_logging_level=None, seed=None, enable_tensorboard=False, outdir_id_style='timestamp', default_writer_kwargs=None, init_kwargs_per_instance=None, thread_shared_data=None)[source]¶
Bases:
objectClass to train, optimize hyperparameters, evaluate and gather statistics about an agent.
- Parameters:
- agent_class
Class of the agent.
- train_envtuple (constructor, kwargs)
Environment used to initialize/train the agent.
- fit_budgetint
Budget used to call
rlberry.agents.agent.Agent.fit(). If None, must be given infit_kwargs['fit_budget'].- eval_envTuple (constructor, kwargs)
Environment used to evaluate the agent. If None, set to
train_env.- init_kwargsdict
Arguments required by the agent’s constructor. Shared across all n_fit instances.
- fit_kwargsdict
Extra arguments to call
rlberry.agents.agent.Agent.fit().- eval_kwargsdict
Arguments required to call
rlberry.agents.agent.Agent.eval(). if eval was not overwritten it’s (AgentWithSimplePolicy) : eval_horizon : int, default: 10**5Horizon, maximum episode length.
- n_simulationsint, default: 10
Number of Monte Carlo simulations.
- gammadouble, default: 1.0
Discount factor.
- agent_namestr
Name of the agent. If None, set to agent_class.name
- n_fitint
Number of agent instances to fit.
- output_dirstr or
pathlib.Path Directory where to store data.
- parallelization: {‘thread’, ‘process’}, default: ‘thread’
Whether to parallelize agent training using threads or processes.
- max_workers: None or int, default: None
Number of processes/threads used in a call to fit(). If None and parallelization=’process’, it will default to the number of processors on the machine. If None and parallelization=’thread’, it will default to the number of processors on the machine, multiplied by 5.
- mp_context: {‘spawn’, ‘fork’, ‘forkserver}, default: ‘spawn’.
Context for python multiprocessing module. Warning: If you’re using JAX or PyTorch, it only works with ‘spawn’.
If running code on a notebook or interpreter, use ‘fork’. forkserver and fork are available on Unix OS only.
- worker_logging_levelstr, default: None
Logging level in each of the threads/processes used to fit agents. If None, use default logger level.
- seed
numpy.random.SeedSequence,Seederor int, defaultNone Seed sequence from which to spawn the random number generator. If None, generate random seed. If int, use as entropy for SeedSequence. If seeder, use seeder.seed_seq
- enable_tensorboardbool, defaultFalse
If True, enable tensorboard logging in Agent’s
DefaultWriter.- outdir_id_style: {None, ‘unique’, ‘timestamp’}, default = ‘timestamp’
If None, data is saved to output_dir/manager_data/<AGENT_NAME_> If ‘unique’, data is saved to
output_dir/manager_data/<AGENT_NAME_UNIQUE_ID>If ‘timestamp’, data is saved tooutput_dir/manager_data/<AGENT_NAME_TIMESTAMP_SHORT_ID>- default_writer_kwargsdict
Optional arguments for
DefaultWriter. Typically one may want to change the log style with default_writer_kwargs set to {“style_log”:”progressbar”} or{“style_log”:”one_line”}
- init_kwargs_per_instanceList[dict] (optional)
List of length
n_fitcontaining the params to initialize each of then_fitagent instances. It can be useful if different instances require different parameters. If the same parameter is defined byinit_kwargsandinit_kwargs_per_instance, the value given byinit_kwargs_per_instancewill be used. Attention: parameters that are passed individually to each agent instance cannot be optimized in the method optimize_hyperparams().- thread_shared_datadict, optional
Data to be shared among agent instances in different threads. If parallelization=’process’, data will be copied instead of shared.
- Attributes:
- output_dir
pathlib.Path Directory where the manager saves data.
- rlberry_version: str
Current version of rlberry. This is saved when calling experiment_manager.save() and it is then used in load() to warn if the version of the agent is not a match with current rlberry version.
- output_dir
Notes
If parallelization=”process” and mp_context=”spawn” or mp_context=”forkserver”, make sure your main code has a guard if __name__ == ‘__main__’. See https://docs.python.org/3/library/multiprocessing.html#multiprocessing-programming.
Examples
>>> from rlberry.agents.torch import A2CAgent >>> from rlberry.envs import gym_make >>> from rlberry.manager import ExperimentManager >>> manager = ExperimentManager( >>> A2CAgent, >>> (env_ctor, env_kwargs), >>> fit_budget=100, >>> eval_kwargs=dict(eval_horizon=500) >>> n_fit=1, >>> parallelization="spawn" >>> ) >>> if __name__ == '__main__': >>> manager.fit(1e4)
Methods
Return an instantiated and reseeded evaluation environment.
Delete files from output_dir/agent_handlers that are managed by this class.
Delete output_dir and all its data.
eval_agents([n_simulations, eval_kwargs, ...])Evaluate managed agents using their 'eval' method and return a list with the results.
fit([budget])Fit the agent instances in parallel.
generate_profile([budget, fname])Do a fit to produce a profile (i.e.
Returns a list containing
n_fitagent instances.Return a dataframe containing data from the writer of the agents.
load(filename)Loads an ExperimentManager instance from a file.
optimize_hyperparams([n_trials, timeout, ...])Run hyperparameter optimization and updates init_kwargs with the best hyperparameters found.
save()Save ExperimentManager data to
output_dir.set_writer(idx, writer_fn[, writer_kwargs])Defines the writer for one of the managed agents.
- build_eval_env() Env | Tuple[Callable[[...], Env], Mapping[str, Any]][source]¶
Return an instantiated and reseeded evaluation environment.
- Returns:
types.EnvInstance of evaluation environment.
- clear_handlers()[source]¶
Delete files from output_dir/agent_handlers that are managed by this class.
- eval_agents(n_simulations: int | None = None, eval_kwargs: dict | None = None, agent_id: int | None = None, verbose: bool | None = True) List[float][source]¶
Evaluate managed agents using their ‘eval’ method and return a list with the results.
- Parameters:
- n_simulationsint, optional
The total number of agent evaluations (‘eval’ calls) to perform. If None, set to 2*(number of agents).
- eval_kwargsdict, optional
A dictionary containing arguments to be passed to the ‘eval’ method of each trained instance. If None, the default set of evaluation arguments will be used (self.eval_kwargs).
- eval_horizonint, default: 10**5
Horizon, maximum episode length.
- n_simulationsint, default: 10
Number of Monte Carlo simulations.
- gammadouble, default: 1.0
Discount factor.
- agent_id: int, optional
The index of the agent to be evaluated. If None, an agent will be chosen randomly for evaluation.
- verbose: bool, optional
Determines whether to print a progress report during the evaluation.
- Returns:
- list of float
A list of length ‘n_simulations’, containing the evaluation results obtained from each call to the
eval()method.
Notes
This method facilitates the evaluation of multiple managed agents by calling their ‘eval’ method with the specified evaluation parameters.
The ‘n_simulations’ parameter specifies the total number of evaluations to perform. Each evaluation will be conducted on one of the managed agents.
The ‘eval_kwargs’ parameter allows you to customize the evaluation by passing specific arguments to the ‘eval’ method of each agent. If not provided, the default evaluation arguments (self.eval_kwargs) will be used.
The ‘agent_id’ parameter is used to specify a particular agent for evaluation. If None, an agent will be chosen randomly for evaluation.
The ‘verbose’ parameter determines whether a progress report will be printed during the evaluation process.
Examples
>>> from rlberry.agents import ExperimentManager >>> eval_kwargs = { 'horizon': 1000, 'n_simulations': 10, 'gamma': 0.99 } >>> agent_manager = ExperimentManager(..., eval_kwargs=eval_kwargs) >>> # evaluation_results will return 5 values (n_simulations=5) where each value is the Monte-Carlo >>> # evaluation over 10 simulations ((eval_kwargs["n_simulation"])) >>> evaluation_results = agent_manager.eval_agents(n_simulations=5, verbose=True)
- fit(budget=None, **kwargs)[source]¶
Fit the agent instances in parallel.
- Parameters:
- budget: int or None
Computational or sample complexity budget.
- generate_profile(budget=None, fname=None)[source]¶
Do a fit to produce a profile (i.e. the cumulative time spent on each operation done during a fit). The 20 first lines are printed out and the whole profile is saved in a file. See `https://docs.python.org/3/library/profile.html`_ for more information on python profiler.
- Parameters:
- budget: int or None, default=None
budget of the fit done to generate the profile
- fname: string or None, default=None
name of the file where we save the profile. If None, the file is saved in self.output_dir/self.agent_name_profile.prof.
- get_agent_instances()[source]¶
Returns a list containing
n_fitagent instances.- Returns:
- list of
Agent n_fitinstances of the managed agents.
- list of
- get_writer_data()[source]¶
Return a dataframe containing data from the writer of the agents.
- Returns:
pandas.DataFrameData from the agents’ writers.
- classmethod load(filename)[source]¶
Loads an ExperimentManager instance from a file.
- Parameters:
- filename: str or :class:`pathlib.Path`
- Returns:
rlberry.manager.ExperimentManagerLoaded instance of ExperimentManager.
- optimize_hyperparams(n_trials=256, timeout=60, n_fit=2, n_optuna_workers=2, optuna_parallelization='thread', sampler_method='optuna_default', pruner_method='halving', continue_previous=False, fit_fraction=1.0, sampler_kwargs=None, disable_evaluation_writers=True, custom_eval_function=None)[source]¶
Run hyperparameter optimization and updates init_kwargs with the best hyperparameters found.
- Currently supported sampler_method:
‘random’ -> Random Search ‘optuna_default’ -> TPE ‘grid’ -> Grid Search ‘cmaes’ -> CMA-ES
- Currently supported pruner_method:
‘none’ ‘halving’
- Parameters:
- n_trials: int
Number of agent evaluations
- timeout: int
Stop study after the given number of second(s). Set to None for unlimited time.
- n_fit: int
Number of agents to fit for each hyperparam evaluation.
- n_optuna_workers: int
Number of workers used by optuna for optimization.
- optuna_parallelization‘thread’ or ‘process’
Whether to use threads or processes for optuna parallelization.
- sampler_methodstr
Optuna sampling method.
- pruner_methodstr
Optuna pruner method.
- continue_previousbool
Set to true to continue previous Optuna study. If true, sampler_method and pruner_method will be the same as in the previous study.
- fit_fractiondouble, in ]0, 1]
Fraction of the agent to fit for partial evaluation (allows pruning of trials).
- sampler_kwargsdict or None
Allows users to use different Optuna samplers with personalized arguments.
- evaluation_functioncallable(agent_list, eval_env, **kwargs)->double, default: None
Function to maximize, that takes a list of agents and an environment as input, and returns a double. If None, search for hyperparameters that maximize the mean reward.
- evaluation_function_kwargsdict or None
kwargs for evaluation_function
- disable_evaluation_writersbool, default: True
If true, disable writers of agents used in the hyperparameter evaluation.
- custom_eval_functionCallable
Takes as input a list of trained agents and output a scalar. If given, the value of custom_eval_funct(trained_agents) is optimized instead of mean([agent.eval() for agent in trained_agents]).
- Returns:
- dict
Optimized hyperparameters.
- save()[source]¶
Save ExperimentManager data to
output_dir.Saves object so that the data can be later loaded to recreate an ExperimentManager instance.
- Returns:
pathlib.PathFilename where the ExperimentManager object was saved.
- set_writer(idx, writer_fn, writer_kwargs=None)[source]¶
Defines the writer for one of the managed agents.
- Parameters:
- writer_fncallable, None or ‘default’
Returns a writer for an agent, e.g. tensorboard SummaryWriter, rlberry DefaultWriter. If ‘default’, use the default writer in the Agent class. If None, disable any writer
- writer_kwargsdict or None
kwargs for writer_fn
- idxint
Index of the agent to set the writer (0 <= idx < n_fit). ExperimentManager fits n_fit agents, the writer of each one of them needs to be set separately.
Examples using rlberry.manager.ExperimentManager¶
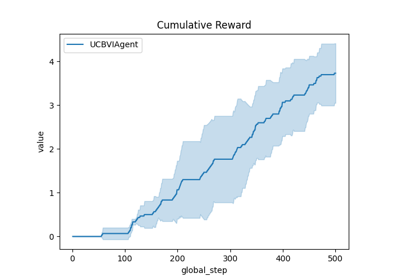
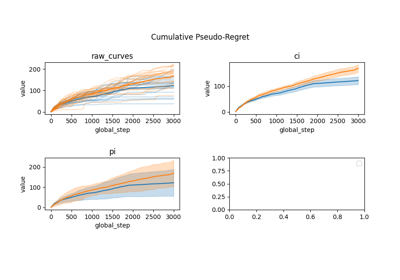
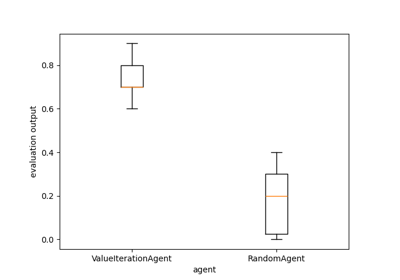
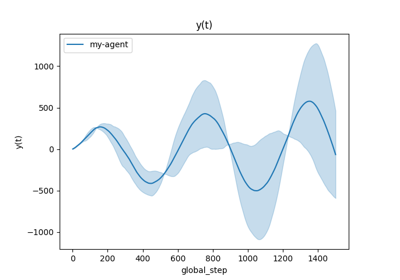

A demo of ATARI Atlantis environment with vectorized PPOAgent
A demo of ATARI Breakout environment with vectorized PPOAgent

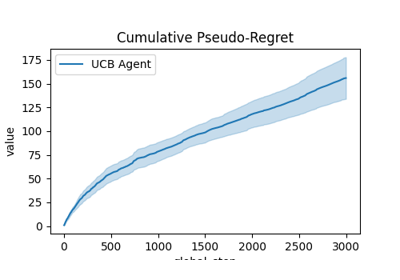
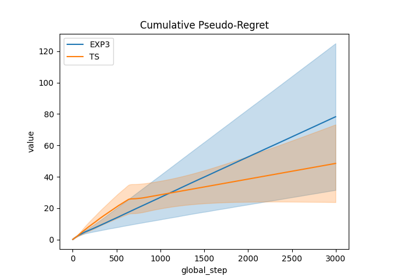
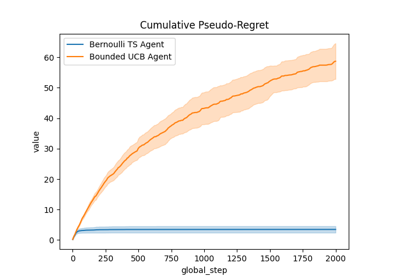
Comparison of Thompson sampling and UCB on Bernoulli and Gaussian bandits
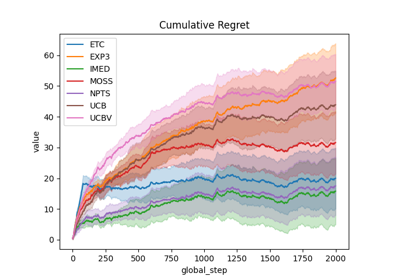
Comparison subplots of various index based bandits algorithms
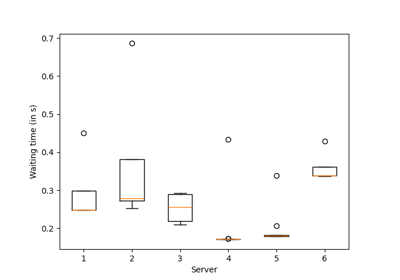
A demo of Bandit BAI on a real dataset to select mirrors